Gold Standard: Standardizing RWD
If real-world data is to deliver on its promise, it needs to be standardized

Within healthcare circles, the hype around the potential of real-world evidence to transform health outcomes through new patient insights has been considerable.

But as the pool of RWD swells daily – driven by growing demand from drug development, regulatory decision-making and patient care and enhanced by advances in technology, study design and data collection methods – there is one very large stumbling block on the horizon.
“As data is collected in multiple languages, formats, ontologies, structures, and platforms, you end up with a Tower of Babel challenge,” says Nigel Hughes, Scientific Director, Janssen Clinical Innovation – Patient Data for Research, Belgium.
The question facing everyone in healthcare right now is simple, says Shahid Hanif, Head of Health Data and Outcomes at The Association of the British Pharmaceutical Industry (ABPI). “How can we reduce variations in data and try to improve its quality?”
The question may be simple, but the answer is unlikely to be, yet many experts agree that data standardization – bringing data into a common format – would represent a major leap forwards.
“At some point, we will need international standards that are widely applicable to different types and levels of quality and rigor of real-world evidence data sources,” says Ivan John Clement, Consultant Data Scientist for Real-World Insights at IQVIA.
This article is from our latest 'Trends in Real-World Evidence' magazine. Download for free.
A Herculean task?
 The banking industry – often compared to healthcare due to similar levels of regulation – may offer some insight, says Hassan Chaudhury, Director and Co-founder at Health iQ.
The banking industry – often compared to healthcare due to similar levels of regulation – may offer some insight, says Hassan Chaudhury, Director and Co-founder at Health iQ.
“Citibank manages untold billions and makes sure that credit flows through from, say, New York to London. They need to track credit, use different systems and have regulators using different systems, as well as talk to different lenders. They all work with each other in microseconds and on different platforms.”
If banks can do it, why not healthcare? “The financial system has a finite number of currencies, essentially a common variable set (for example, US dollars of British pounds) and diversity in systems,” says Hughes.
“In healthcare, hardly anyone is capturing raw data the same way, and the variable set for healthcare, based on such heterogeneity of disease, is a vast voluminous array of variables, collected in an almost infinite way.”
One lesson from banking is the use of common data models (CDMs). According to the European Medicines Agency (EMA), which held a workshop late last year on the feasibility of CDMs in European healthcare, such models are “a mechanism by which raw data are standardized to a common structure, format and terminology independently from any particular study in order to allow a combined analysis across several databases/datasets.”
Some notable CDMs showing great promise
The Observational Medical Outcomes Partnership
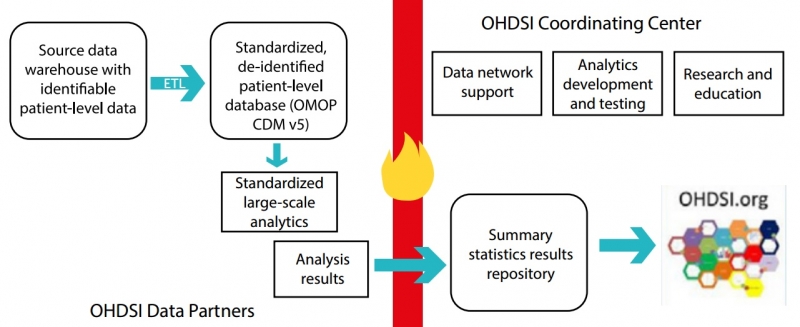
The OMOP model was developed by the multi-stakeholder, academic and pharmaceutical collaboration OHDSI (Observational Health Data Sciences and Informatics).
It currently enables the systematic analysis of over 82 datasets and 1.2 billion health records from 17 countries (and growing), transforming the data from databases into a common format and representation prior to analysis (see below).
Chaudhury offers a simple explanation: “If Dataset A is an electronic health record (EHR), but Dataset B is an administrative record, OMOP helps to translate the two distinct datasets in a way that you can now link them in a standard way.”
In addition, the model uses a standardized vocabulary of disease and drug terminology, which speeds up observational research.
Initially used in the US, the OMOP has since been applied in Europe, specifically as part of the Innovative Medicines Initiative (IMI) European Medical Information Framework (EMIF) and European Health Data Network (EHDEN).
EMIF was a five-year IMI project that ended in June 2018 to develop a common data framework for patient-level data. Hughes, who was EMIF Platform Coordinator, explains that the development of EMIF focused on harmonizing two data streams via the OMOP CDM – cohort and population data – to support federated identification, assessment, use, and reuse of RWD.
EHDEN is another European IMI five-year project that will build on the EMIF’s work by creating a federated network of RWD sources. “It aims to harmonize approximately 100 million EHRs in the European Union by utilizing the OMOP CDM. It will focus mostly on population data sources and outcomes-based research for validation,” says Hughes.
The Sentinel System
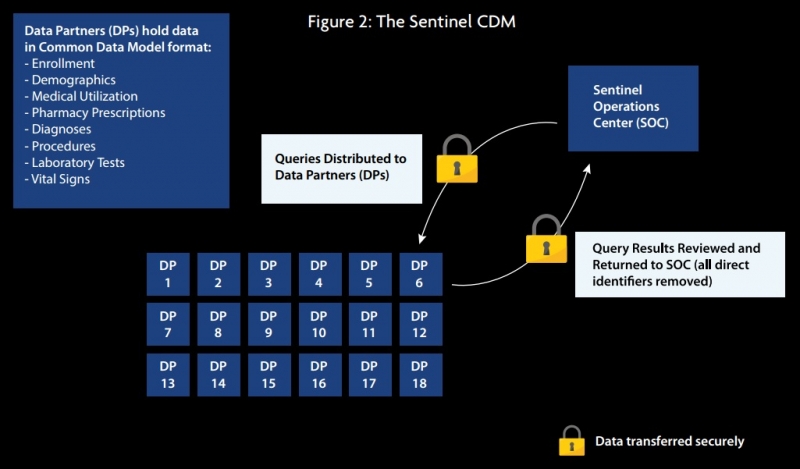
The Sentinel CDM, launched and financed by the US Food and Drug Administration (FDA) in 2016, uses a “distributed querying approach” that enables an automated query and response process, generating RWE to support regulatory and healthcare provider decision-making. The CDM currently has 66.9 million members who are adding medical and drug coverage data and 292.5 million patient identifiers.
The system mainly comprises claims, EHR, and registry data, although it is a flexible system that can support any type of data analysis and can therefore be used with any data source.
As seen in figure 2, data partners (DP) transform data enquiries locally using standardized computer programs, before reviewing the results and sending them back to Sentinel, who can then distribute them. Lead data partners are Harvard Pilgrim Health Care Institute and Harvard Medical School, but the system includes many other data partners such as IQVIA, Humana and Aetna.
The National Patient-Centered Clinical Research Network
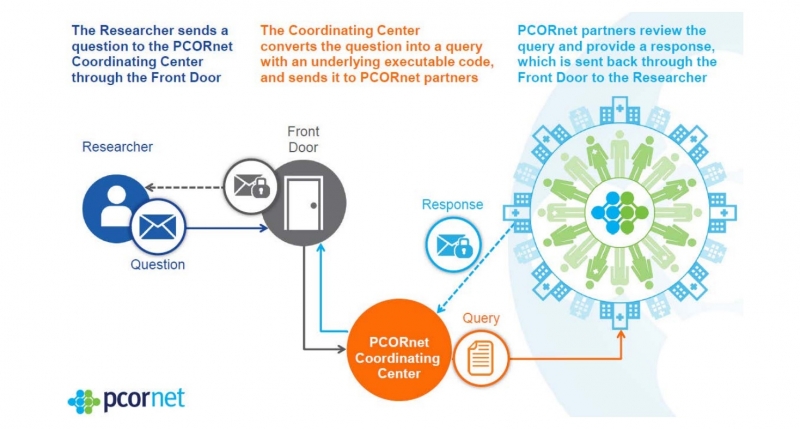
The PCORnet coordinates the standardization of data across almost 80 clinical sites nationwide, facilitating large-scale comparative effectiveness research. It has been called a “network of networks” because it comprises data from patient research networks, clinical data research networks, and health plan research networks.
Based on the Sentinel CDM, the PCORnet operates an infrastructure whereby data queries from researchers pass through a coordinating center for data standardization before being sent back to the researcher (see figure 3). The key aim is to make collaborative observational and clinical research easier through consistent terminology and data organization in the form of standardized codes.
As an example, even something as simple as date of birth will be coded differently across researchers. One may code it is ‘Date_ of_Birth,’ another as ‘DOB,’ and another as ‘DB.’ The PCORnet provides the universal code of ‘BIRTH_DATE’ so that however an organization has labelled this variable, it can be mapped to this universal code.
Impressive results
The potential for such common data models to streamline RWE generation and harmonize healthcare is an exciting prospect for anyone with a passion for advancing patient-centered outcomes.
Indeed, OHDSI recently showcased the power of their OMOP CDM during a one-day symposium; they used standardized observational datasets to run a study that took as little as two hours. The outcome was the development of 21 prediction models for different outcomes within people with depression. These models are now available for other researchers to reproduce and test.
Despite how impressive these CDMs are, the next challenge is harmonizing the separate models. This is something the FDA Center for Drug Examination & Research are working towards with their PCORTF (Patient-Centered Outcomes Research Trust Fund) Common Data Model Harmonization for Evidence Generation Project. This is the space to watch.
 In the meantime, the importance of stakeholder involvement in data standardization must never be overlooked, says Hanif. “Reducing variety in data is an incremental process whereby patients, clinicians and others can see the benefit of standardizing. People need to see the value or return on the information that is captured.”
In the meantime, the importance of stakeholder involvement in data standardization must never be overlooked, says Hanif. “Reducing variety in data is an incremental process whereby patients, clinicians and others can see the benefit of standardizing. People need to see the value or return on the information that is captured.”
Indeed, demonstrating the value of data standardization can help to ensure that healthcare is not deprived of the future benefits and opportunities of more optimal uses of RWD. As Chaudhury says: “If we are not going to find a way to connect datasets and make them work in a streamlined manner, the industry, the system and the patients will suffer.”
This article was first published in Trends in Real-World Evidence in December 2018. To download a free copy, click here.